

概述:
根据要素位置和属性值使用 Global Moran’s I 统计量测量空间自相关性。提出者为澳大利亚统计学家帕特里克·阿尔弗雷德·皮尔斯·莫兰(Patrick Alfred Pierce Moran)。
Moran PAP. The interpretation of statistical maps[J]. Journal of the Royal Statistical Society B , 1948,(37):243-251.
详细概述:
空间自相关 (Global Moran’s I)工具同时根据要素位置和要素值来度量空间自相关。在给定一组要素及相关属性的情况下,该工具评估所表达的模式是聚类模式、离散模式还是随机模式。该工具通过计算 Moran’s I指数值、z得分和p值来对该指数的显著性进行评估。p值是根据已知分布的曲线得出的面积近似值(受检验统计量限制)。
公式:

说明:
1、空间自相关工具返回五个值:Moran’s I 指数、预期指数、方差、z 得分及 p 值。您可通过结果窗口访问这些值,也可以将这些值作为派生输出值进行传递,以满足模型或脚本中的潜在使用需要。
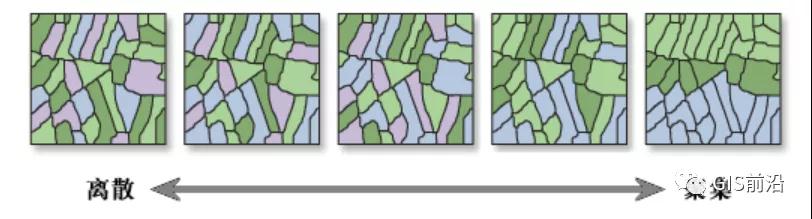
在给定一组要素及相关属性的情况下,该工具评估所表达的模式是聚类模式、离散模式还是随机模式。使用 z 得分或 p 值指示统计显著性时,如果 Moran’s I 指数值为正则指示聚类趋势,如果 Moran’s I 指数值为负则指示离散趋势。
2、返回的z得分与P值解释:
p 值不具有统计学上的显著性。
不能拒绝零假设。要素值的空间分布很有可能是随机空间过程的结果。观测到的要素值空间模式可能只是完全空间随机性 (CSR) 的众多可能结果之一。
p 值具有统计学上的显著性,且 z 得分为正值。
可以拒绝零假设。如果基础空间过程是随机的,则数据集中高值和/或低值的空间分布在空间上聚类的程度要高于预期。
p 值具有统计学上的显著性,且 z 得分为负值。
可以拒绝零假设。如果基础空间过程是随机的,则数据集中高值和低值的空间分布在空间上离散的程度要高于预期。离散空间模式通常会反映某种类型的竞争过程:具有高值的要素排斥具有高值的其他要素;具有低值的要素排斥具有低值的其他要素。
常见的问题:
Q1:可以针对不同研究区域使用全局自相关生成的 z 得分或 p 值与分析结果进行比较吗?
不可以。但是,如果研究区域是固定的(例如,所有分析都针对加利福尼亚的县)、输入字段具有可比性(例如,所有分析都涉及某种类型的人口计数),并且工具参数均相同(例如,距离范围或距离阈值为 5,000 米的“固定距离”并且工具均使用“行标准化”参数),此时,便可对统计学上显著的 z 得分进行比较,以了解空间聚类或空间离散的程度或更好地了解趋势随时间推移的变化情况。还可以在不断增大距离范围或距离阈值的情况下运行分析,以了解在哪个距离/比例下促进空间聚类的过程最明显。
Q2:为何会得到大于 1.0 或小于 -1.0 的 Moran’s I 指数?
通常,Global Moran’s I 指数介于 -1.0 到 1.0 之间。只有对权重进行了行标准化时才会这样。如果未对权重进行行标准化处理,则指数值可能会落在 -1.0 到 1.0 的范围之外,这表示参数设置有问题。
Q3:何时采用全局莫兰指数(Global Moran’s I),何时采用局部莫兰指数(Local Moran’s I),以及,两者有何区别?
莫兰指数分为全局莫兰指数(Global Moran’s I)和局部莫兰指数(Local Moran’s I),前者是Patrick Alfred Pierce Moran于1950年提出,用来衡量空间自相关程度的度量;后者是美国亚利桑那州立大学地理与规划学院院长 Luc Anselin 教授在1995年提出的。
通常情况,先做一个地区的全局指数,全局指数只是告诉我们空间是否出现了集聚或异常值,但并没有告诉我们在哪里出现。换句话说全局Moran’I只回答Yes还是NO;如果全局有自相关出现,接着做局部自相关;局部Moran’I会告诉我们哪里出现了异常值或者哪里出现了集聚,是一个回答Where的工具。
莫兰指数是一个有理数,经过方差归一化之后,它的值会被归一化到-1.0与+1.0之间。
Moran’s I大于0时,表示数据呈现空间正相关,其值越大空间相关性越明显;Moran’s I小于0时,表示数据呈现空间负相关,其值越小空间差异越大;Moran’s I为0时,空间呈随机性。
ArcGIS中运行莫兰指数的注意事项:
输入字段严重偏斜(创建数据值的直方图可了解此情况),空间关系的概念化或距离范围的设置使得某些要素的相邻要素非常少。Global Moran’s I 统计量是渐进正态的,这意味着,对于偏斜数据,每个要素至少需要具有 8 个相邻要素。为距离范围或距离阈值参数计算的默认值可确保每个要素至少具有 1 个相邻要素,但这可能不够,尤其是在输入字段中的值严重偏斜时。
使用反距离空间关系的概念化,并且反距离非常小。
未选择行标准化。除非聚合方案与所分析的字段直接相关,否则,只要对数据进行了聚合处理,就应选择行标准化。
空间关系的概念化:
指定要素空间关系的定义方式。
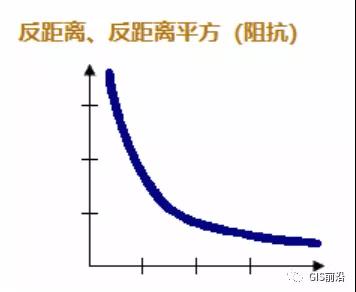
INVERSE_DISTANCE—与远处的要素相比,附近的邻近要素对目标要素的计算的影响要大一些。
INVERSE_DISTANCE_SQUARED—与 INVERSE_DISTANCE 类似,但它的坡度更明显,因此影响下降得更快,并且只有目标要素的最近邻域会对要素的计算产生重大影响。
反距离方法(INVERSE_DISTANCE、INVERSE_DISTANCE_SQUARED)最适合对连续数据,或最适合对符合此种情形的对象进行建模:两个要素在空间上越靠近,它们彼此交互/影响的可能性就越大。使用此空间概念化参数,每个要素都可能是其他各个要素的邻域,而对于大型数据集,这将涉及巨大的计算量。使用反距离法时,应尝试添加一个距离范围或距离阈值,特别是对于大型数据集十分重要。如果将距离范围或距离阈值参数留空,系统将计算距离阈值,但这可能不是分析所需的最适当距离;默认的距离阈值是能够确保每个要素至少具有一个相邻要素的最小距离。
可为0,可默认,可输入正值。
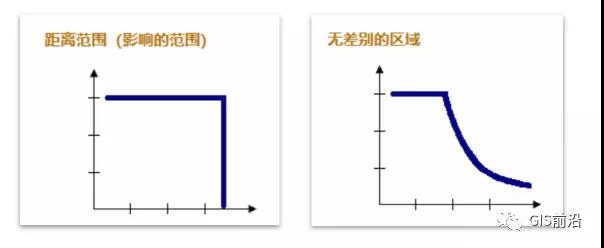
FIXED_DISTANCE_BAND—将对邻近要素环境中的每个要素进行分析。在指定临界距离(距离范围或距离阈值)内的邻近要素将分配有值为 1 的权重,并对目标要素的计算产生影响。在指定临界距离外的邻近要素将分配值为零的权重,并且不会对目标要素的计算产生任何影响。此方法适用于处理点数据。
ZONE_OF_INDIFFERENCE—在目标要素的指定临界距离(距离范围或距离阈值)内的要素将分配有值为1的权重,并且会影响目标要素的计算。一旦超出该临界距离,权重(以及邻近要素对目标要素计算的影响)就会随距离的增加而减小。
不可为0,可默认,可输入正值。
CONTIGUITY_EDGES_ONLY—只有共用边界或重叠的相邻面要素会影响目标面要素的计算。
CONTIGUITY_EDGES_CORNERS—共享边界、结点或重叠的面要素会影响目标面要素的计算。
国际象棋里面的Rook(车)和皇后(Queen)的走法,因此也叫做Rook’s Case和Queen’s Case。面要素计算进行计算的话,面邻接是最简单的一种空间关系概念化的模型。
GET_SPATIAL_WEIGHTS_FROM_FILE—将由指定空间权重文件定义空间关系。指向空间权重文件的路径由权重矩阵文件参数指定。
标准化:
行标准化的权重通常与固定距离相邻要素结合使用,并且几乎总是用于基于面邻接的相邻要素,这样可减少因为要素具有不同数量的相邻要素而产生的偏离。行标准化将换算所有权重,使它们在 0 和 1 之间,从而创建相对(而不是绝对)权重方案。每当要处理表示行政边界的面要素时,您都可能会希望选择“行标准化”选项。
实例:
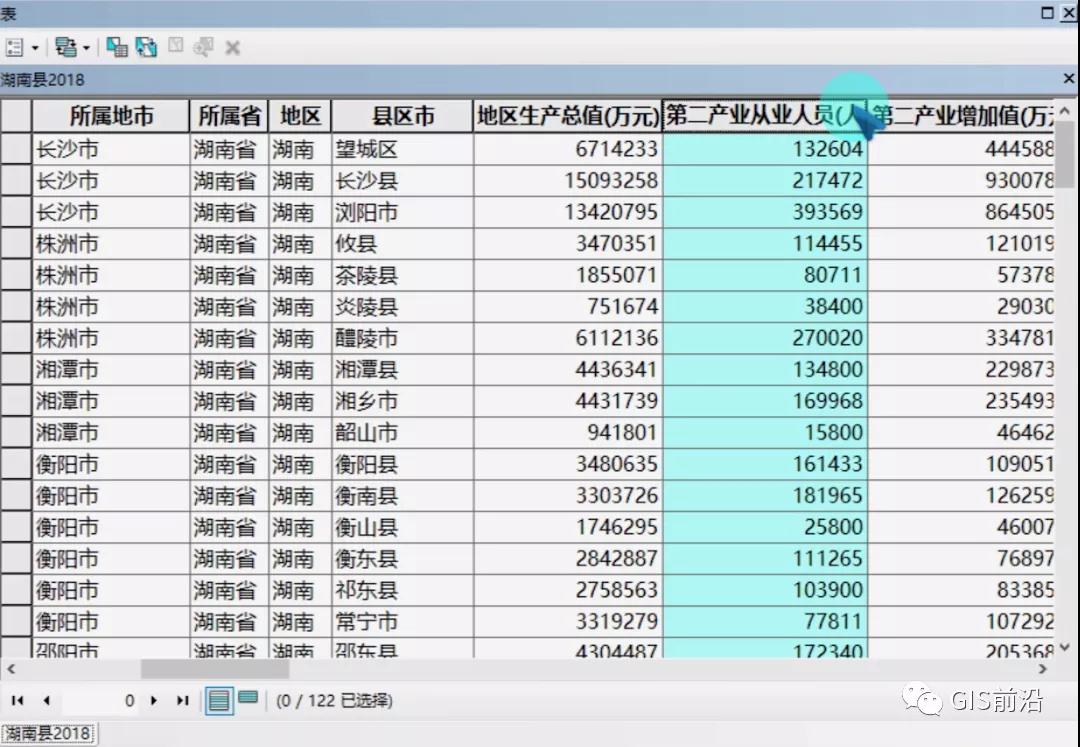
这次,我们采用湖南省2018年的122个县的一些社会经济数据,如GDP、第二产业增加值、第二产业从业人员、第三产业增加值、学校、医院床位等等数据,来进行莫兰指数的实验:
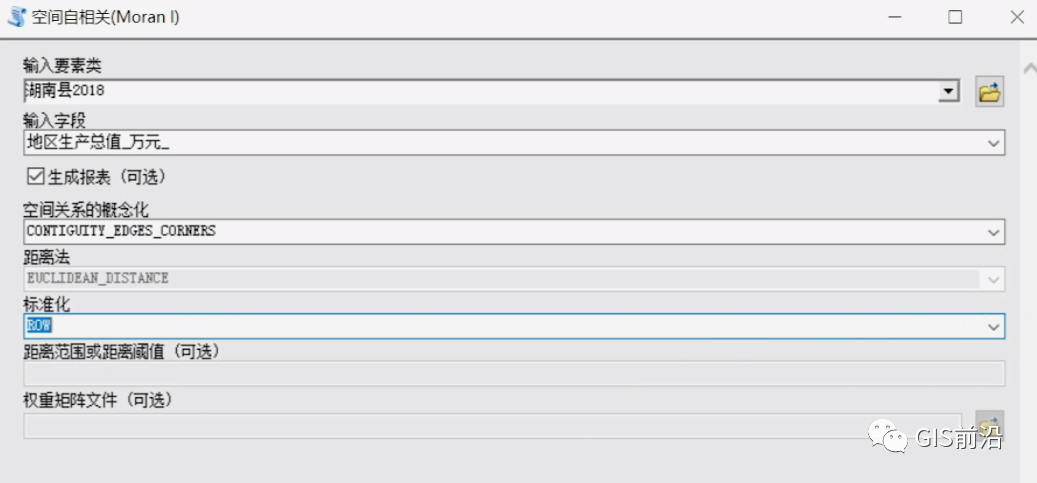
之前的参数设置都已经讲过了,所以我们直接按照上方的提示设定参数,其实莫兰指数的参数蛮少,主要就一个:空间关系的概念化。
因为首先,空间关系的概念化选择决定了你要不要设置距离范围或距离阈值以及权重矩阵文件,如果你选择了反距离,那么距离范围可以不输入,也可以选择输入;如果选择了FIXED_DISTANCE_BAND或者ZONE_OF_INDIFFERENCE,那么最好输入距离范围,当然也可以不输入,选择默认;如果选择了CONTIGUITY_EDGES_ONLY或者CONTIGUITY_EDGES_CORNERS,则不需要输入距离范围,选择了GET_SPATIAL_WEIGHTS_FROM_FILE,那当然需要引入权重矩阵文件了!
其次,距离法一般我们也都是选择欧氏距离,标准化一般都是默认勾选ROW的。那么我们按照以下的进行选择,然后点击生成报表,运行。
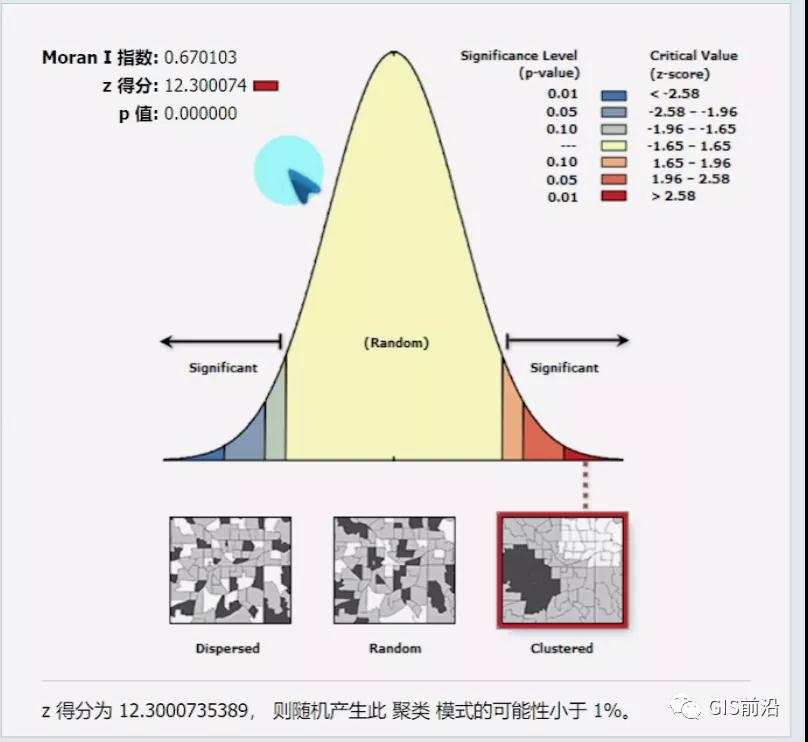
最终会生成一张报表如下,而不是返回给我们一张花花绿绿的图(那是局部莫兰指数或者其他空间统计工具会生成的),因为上面已经讲到,其实莫兰指数就是告诉我们要素是否是随机分布的,也就是说只会给我们一个值,是或者否,仅此而已:
本文链接:https://ue4gis.com/blog/383.html
本文标签:ArcGIS











