

摘要:为减少铁路设计项目中土地外业调查工作量,提高征地数量统计准确性,提出利用土地利用数据库和基本农田数据库,基于空间相交分析和空间擦除分析计算征地数量的方法,实现快捷、准确的铁路设计项目用地数量的计算统计。与传统的依赖人工外业土地调查作业来统计铁路征地数量的计算方法相比,该方法可显著提高内业统计效率与征地数量准确度,为铁路设计项目带来一定的经济效益。
关键词:铁路;征地;相交分析;擦除分析;数量统计
铁路工程征地费用是铁路工程投资的重要组成部分,铁路设计单位勘察设计深度不够,征地数量统计不准确,会导致设计预算远低于实际征地补偿。
本文基于国土部门土地调查成果,提出基于空间分析的征地数量计算方法,可省去土地外业调查工作,对提高征地数量计算效率和准确性具有重要意义。
01
传统铁路工程征地数量计算方法的问题分析
传统铁路工程征地数量计算是先调查沿铁路线位地块的土地类型(水田、旱地、公路用地、基本农田等)、里程范围、土地性质(集体或国有)
所属行政区划等信息;根据里程范围,结合铁路工程用地界,计算该地块面积,按行政区划、土地权属性质对土地进行分类统计,得到铁路工程征地数量表。
按照传统征地数量计算方法,地块边界并不是真实边界,边界按照直线处理,地块面积不准确, 如图1所示。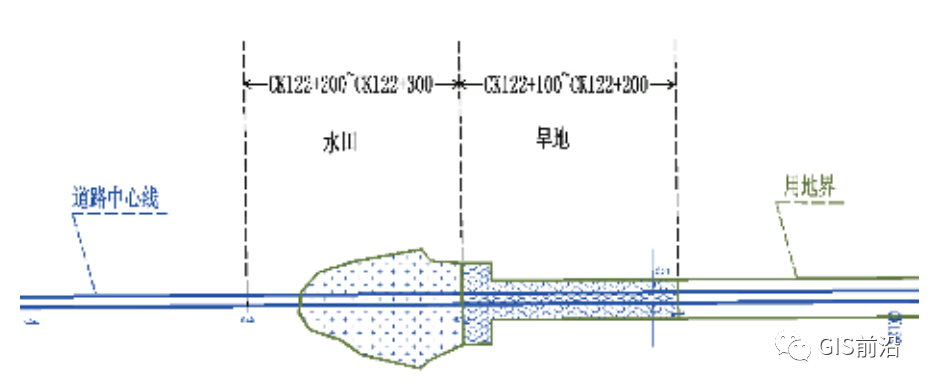
图1 传统征地数量计算方法示意
其次,土地所属行政区划是依据地块座落位置确定的,这种调查方式对于“飞地”存在统计错误。“飞地”是指地块实际落单位与权属单位不同,如位于湖北省麻城市的罗阳村属于武汉市新洲区;此外,基本农田调查依赖基本农田标志牌进行识别,存在人为误差。
综上所述,传统征地数量计算方法需耗费人力和物力开展外业土地调查,内业计算效率低下,还无法保证准确性。当铁路线路设计发生变更,需重新进行外业土地调查。为此,需要一种更为高效、准确的征地数量计算方法。
王志林等人提出一种基于三维激光扫描获取征地拆迁红线内房屋及其附属物、树木植被、电力线等实物的征地数量计算方法。余波提出一种基于实测地形图征地房屋统计方法。这些方法实为计算拆迁数量,并非用地数量。目前,鲜有文章介绍征地数量计算方法。
02
基于空间分析的征地数量计算方法
2.1 数据收集
目前,第三次全国国土调查已取得初步成果,各地区国土部门已更新土地利用数据库和基本农田数据库;其中,基本农田数据库是土地利用数据库的子集。因此,铁路外业勘测时,无需再调查土地,可向铁路线路所经地区的国土部门收集土地利用数据库和基本农田数据库。
土地利用数据库准确记录该地区每块土地的几何坐标、土地权属性质、土地地类名称、土地权属单位信息,其它属性含义可参见第三次全国土地调查技术规程。基本农田数据库记录该地区每块基本农田的几何坐标、土地权属性质、土地地类名称、土地权属单位信息,其它属性含义可参见基本农田数据库标准。图2为土地利用数据库属性信息示例,高亮土地为水田,其属性表中 DLMC、QSXZ、QSDWDM、QSDWMC 分别为地类名称、权属性质、权属单位代码、权属单位名称。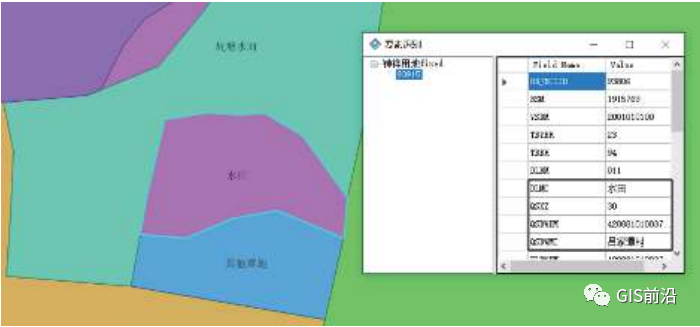
图2 土地利用数据库属性信息示例
地类名称(DLMC)表示土地的类型,比如水田、林地;权属单位名称(QSDWMC)表示土地所属行政区划的名称,该属性往往并不包含完整的行政区划信息,分类统计征地数量时,更多采用权属单位代码(QSDWDM);权属单位代码(QSDWDM)为完整的土地所属行政区划代码,前 6 位数字是省(直辖市)、市、县(县级市)代码,7~12位是乡(镇)、村代码;权属性质(QSXZ)取值见表1。
表1 土地权属性质代码表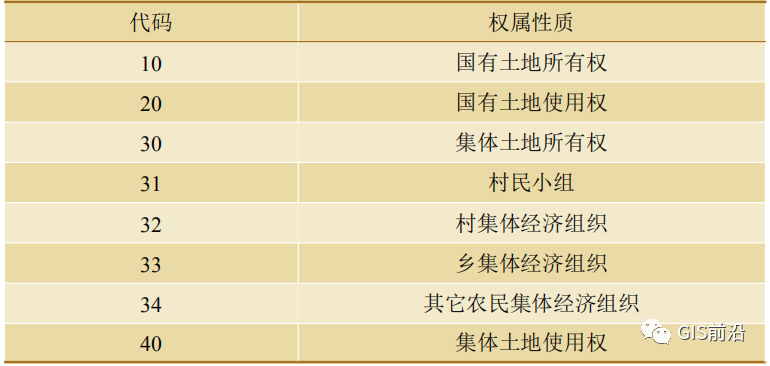
土地利用数据库和基本农田数据库有3种常见
文件格式 :Shapefile、Personal Geodatabase和File
Geodatabase;Shapefile数据库至少包括 “ .shp”、 “.shx”、“.dbf”和“.prj”4 个文件,外业收集数据时需检查收集到的数据库文件是否齐全;其中, “.shp”文件记录几何信息,“.shx”文件记录几何图形的索引,“.dbf”文件记录属性,“.prj”文件记录空间参考信息。Personal Geodatabase 是 Access数据库,文件扩展名为“mdb”;File Geodatabase 数据库是1个文件夹,文件夹名称以“.gdb”结尾。
2.2 铁路征地数量计算方法
先使用土地几何坐标数据计算土地面积,再按土地权属性质、土地地类名称和土地权属单位代码进行土地数量分类统计,铁路征地数量计算流程见图3所示。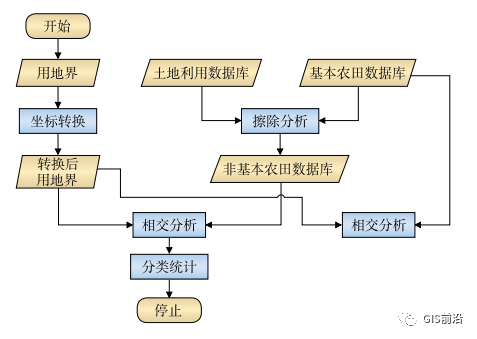
图3 铁路征地数量计算流程
2.2.1 用地界坐标转换
铁路工程坐标参考往往与土地利用数据库和基本农田数据库的坐标参考不一致,进行空间分析前,需对铁路工程用地界进行坐标转换。铁路工程用地界采用笛卡尔平面直角坐标系,测量平面直角坐标系南北方向为X轴,东西方向为Y轴;进行坐标转换时,应先将用地界的X坐标与Y坐标互换,转换为测量平面直角坐标系下坐标值;使用开源跨平台地图投影库Proj.4完成坐标转换,坐标转换完毕之后再将X坐标与Y坐标互换,即可得到与数据库坐标参考一致的坐标值。通过坐标转换,用地界的坐标参考可与土地利用数据库和基本农田数据库的坐标参考保持一致。
2.2.2 空间相交分析
空间相交分析判断2个几何多边形空间上是否相交;若相交,空间相交结果为被相交图形中与相交图形重叠的部分,如图4所示。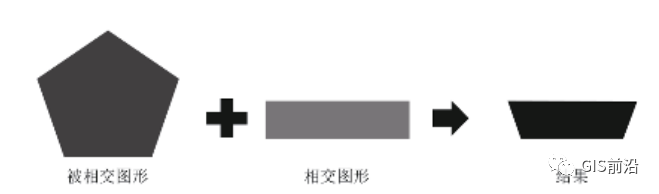
图4 空间相交分析原理示意
将铁路工程用地界与基本农田数据库进行相交分析,可得到用地界范围内的基本农田图形集。
空间相交分析算法描述如下:
IntersectionAnalysis()
{
for each(基本农田图斑 in 基本农田数据库)
{
for each(用地界多边形 in 用地界)
{
//判断图形包围盒是否相交可加速程序运行
if (基本农田图斑包围盒与用地界多边形包围盒有交集)
{
基本农田图斑与用地界多边形相交分析
返回 geo;
if (geo 非空) {
geo 添加至结果集;
}//end if
}//end if
}//end for
}//end for
返回结果集;
}//end function
2.2.3 空间擦除分析
空间擦除分析判断2个几何多边形空间关系上是否相交;若相交,空间擦除结果为被擦除图形与擦除图形不重叠的部分,如图5所示。
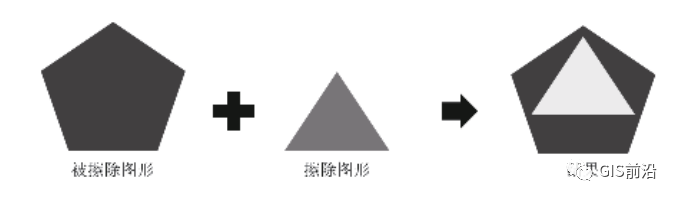
图5 空间擦除分析原理示意
基本农田数据库是土地利用数据库的子集,对铁路工程用地界与土地利用数据库进行相交分析,得到用地界范围内的土地集包含基本农田。为避免重复统计基本农田数量,通过空间擦除分析,从土地利用数据库中剔除基本农田数据,得到非基本农田数据库。
空间擦除分析算法描述如下:
EraseAnalysis()
{
for each(土地利用图斑 in 土地利用数据库)
{
for each(基本农田图斑 in 基本农田数据库)
{
//判断图形包围盒是否相交可加速程序运行
if (土地利用图斑包围盒与基本农田图斑包
围盒有交集)
{ 土地利用图斑与基本农田图斑擦
除分析返回 geo;
if (geo 非空) {
geo 添加至结果集;
}//end if
}//end if
}//end for
}//end for
返回结果集;
}//end function
对土地利用数据库与基本农田数据库进行空间擦除分析,得到的非基本农田数据库不再含有基本农田数据;再将非基本农田数据库与用地界进行相交分析,得到用地界内非基本农田征地数据。
03
征地数量统计方法
通过空间擦除分析和空间相交分析,得到用地界内基本农田数据库和用地界内非基本农田数据库。按权属单位代码 (QSDWDM)、权属性质 (QSXZ) 和地类名称(DLMC),对这2个数据库进行分类统计,得到基本农田数量表和非基本农田数量表。非基本农田征地数量统计与基本农田征地数量统计算法一致,以基本农田征地数量统计为例,阐述详细的计算过程。
3.1 爬取权属单位名称
将基本农田数据库记为NT,数据库中每块土地的 QSDWDM 属性为完整的土地所属行政区划代码,利用爬虫技术解析行政区划的中文名称。
(1)读取 NT 数据库中1条土地记录,记为Land;提取 Land 的QSDWDM属性值,记为DM,属性值前6位数字是省(直辖市)、市、县(县级市)代码,7~12 位是乡(镇)、村代码。国家统计局每年公布全国行政区划代码与行政区划名称对照表,该对照表的访问地址为:http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/Year/index.html,记为 Url;其中,属性Year为国家统计局网站上公布的统计用区划和城乡划分代码的最新年份。
(2)将DM分解为5个部分,每1个部分不足12位时,在其末尾补足数字“0”;行政区划按从大到小,依次记为 DM1,DM2,DM3,DM4,DM5。采用网络爬虫技术,爬取对照表访问地址Url,将DM解析为行政区划名称,如图6所示。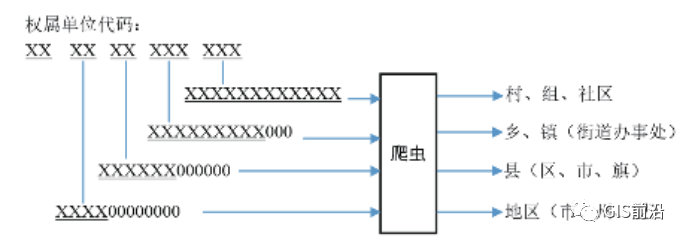
图6 征地所属行政区划名称的爬取过程示意
(3)省(自治区、直辖市)的数量少,且代码固定,直接在程序中设置省(自治区、直辖市)代码与名称的映射关系,根据DM1代码可获取省(自治区、直辖市)名称,记为PName;
(4)利用HtmlAgilityPack 程序集解析对照表访问地址Url所对应的 HTML 代码;设置搜索条件 XPath=“.//tr[@class=’ provincetr’]”,可获取所有省份名称与跳转链接地址集,记为{P};在集合{P}中查找 PName,对应的跳转链地址接记为U1;爬取跳转链地址 U1,使用 XPath=“ .//tr[@class=’citytr’]”作为搜索条件,获取当前省份 (直辖市) 下属所有地区 (市、州、盟) 的代码、名称和跳转链接地址集,记为集合{City}。在集合{City}中查找代码 DM2 对应的地区名称和跳转链接地址,记为U2。
(5)爬取网址U2,设置搜索条件XPath=“.//tr[@class=’countytr’]”,获取当前地区下属所有县 (区、市 、旗 ) 代码 、名称和跳转链接地址集 , 记为{County};在集合{County}中查找代码DM3对应的县名称和跳转链接地址,记为U3。
(6)爬取跳转链接地址U3,设置搜索条件为XPath=“.//tr[@class=’towntr’]”,获取当前县下属所有乡、镇(街道办事处)代码、名称和跳转链接地址集,记为{Town};在集合{Town}中查找代码DM4对应的乡镇名称和跳转链接地址,记为U4。
(7)爬取网址U4, 设置搜索条件XPath=“.//tr[@class=’villagetr’]”,获取当前乡镇下属所有村(组、社区)代码、名称集,记为{Village};在集合{Town}中查找代码DM5对应的村(组、社区)名称。
按以上步骤,通过解析QSDWDM属性值,可得到完整的行政区划名称。
3.2 土地分组统计
读取土地Land的DLMC属性值进行分组,取值“10”或“20”归为国有土地分组,其它归为集体土地分组。
遍历数据库中所有土地,爬取对应的土地行政区划中文名称,按照行政区划名称、权属性质、土地类型进行分组,统计各分组的地块面积,得到用地界内基本农田数量表。
04
应用实践
DotSpatial 是一套开源地理信息系统类库,支持C#编程语言,可用于实现土地利用数据库的可视化;采用C#语言,基于Dotspatial开发征地数量计算统计软件。以安徽省某铁路工程为例,计算基本农田征地数量和非基本农田征地数量。
4.1 基本农田数量计算
提取铁路用地界坐标进行坐标转换,使其坐标参考与基本农田数据库的坐标参考一致,用地界与基本农田数据库的叠加显示见图7。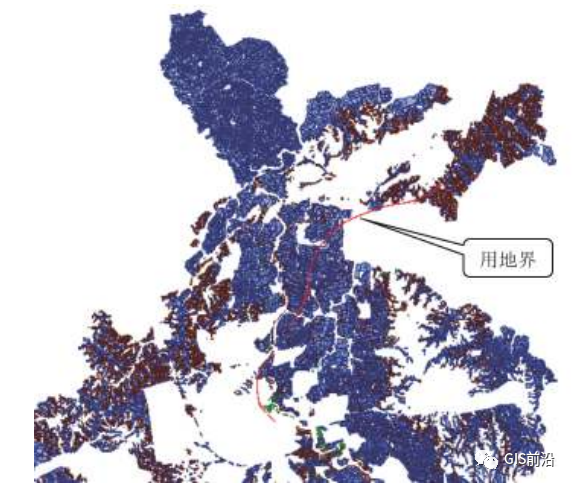
图7 基本农田与用地界的叠加显示
图7中,红色带状区域是经过坐标转换的铁路用地界,基本农田作为被相交图形,用地界作为相交图形进行空间相交分析,得到用地界内基本农田数据库,最后根据数据库的 QSXZ、DLMC、QSDWDM 属性进行分类统计输出基本农田数量表,如图8所示。
图8 相交分析统计结果
在图8中,显示区域(a)为铁路用地界与基本农田数据库相交分析结果,显示区域(b)为分类统计属性字段设置以及行政区划统计级别设置,显示区域(c)为征用基本农田数量统计结果。
4.2 非基本农田数量计算
使用擦除分析方法将从土地利用数据库中擦除与基本农田数据库相交的部分,得到非基本农田数据库,如图9所示。
图9 擦除分析实例
在图9中,(a)为土地利用数据库,(b)为基本农田数据库,(c)为非基本农田数据库。非基本农田数据库与用地界进行空间相交分析,得到用地界内非基本农田数据库,经分类统计,得到非基本农田征地数量表。非基本农田征地数量分类统计与基本农田征地数量分类统计步骤一致,不再赘述。
05
结束语
本文提出铁路征地数量计算方法,利用既有土地利用数据库和基本农田数据库,通过空间相交分析和空间擦除分析,计算出征地面积;利用网络爬虫技术,获取土地所属的行政区划名称,按照行政区划、权属性质、土地名称进行分类统计,得到征地数量统计表。
该方法无需进行土地外业调查作业,可减少外业勘测工作量;此外,当线路平面发生变更时,也无需返工重新进行外业土地调查。与传统土地调查方法相比,土地利用数据库和基本农田数据库提供了更为准确的土地边界和土地权属等信息,征地数量统计也更为精确。基于空间分析的铁路征地数量计算方法不仅适用于铁路永久征地和大临工程等临时征地数量计算,也适用于公路工程。
来源:https://blog.csdn.net/qq_43173805/article/details/118567025
成都途远GIS是一家专业致力于无人机航空摄影测绘、航空数据处理、GIS地理信息系统研发、数字孪生城市制作、数字沙盘模型等业务的创新型科技公司,为您提供一站式地理信息服务。
本文链接:https://ue4gis.com/blog/390.html
本文标签:











